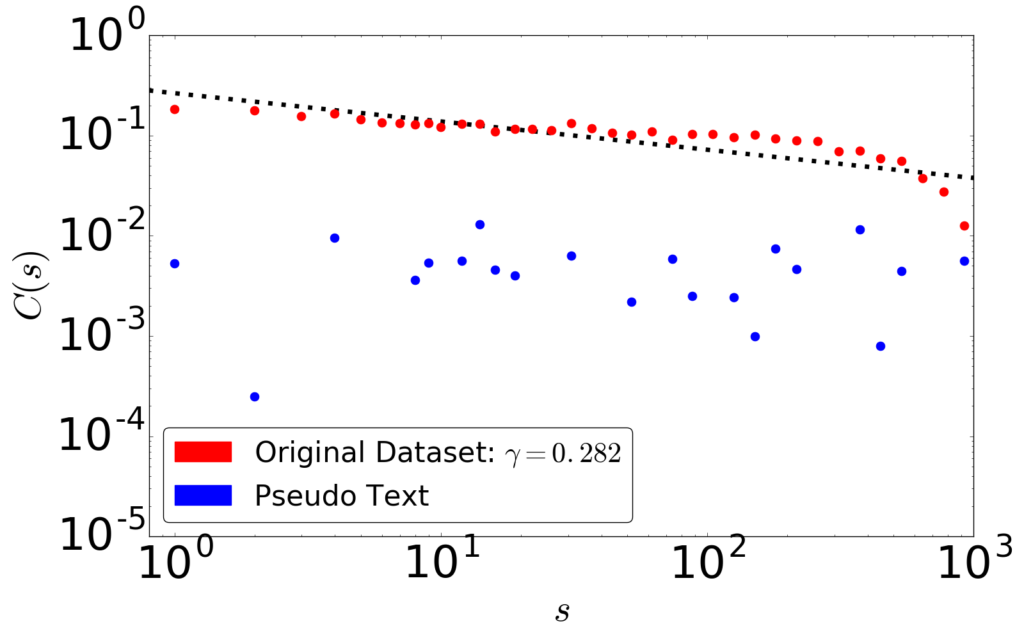
深層学習はデータのどのような側面を捉え、または捉えきれないのでしょうか。 複雑系としての記号の系にはさまざまな経験則が成り立つことが知られています。 研究室では、深層学習が生成する擬似データにどの程度の冪乗則が成り立っているか検証し、 従来の観点からは異なる観点から深層学習を吟味し、深層学習の改良につなげることを考えています。 たとえば右図は、文書は成り立つ長相関が文字レベル深層言語モデルでは成立しないことを示しています。 このような議論は自然言語以外の系、例えば金融市場にも適用することができます。
参考文献
- Shuntaro Takahashi, Kumiko Tanaka-Ishii. Evaluating computational language models with scaling properties of natural language. Computational Linguistics, 2019, 45.3: 481-513. [link]
- Shuntaro Takahashi, Kumiko Tanaka-Ishii. Do neural nets learn statistical laws behind natural language? . PLOS One, 2017, 12.12: e0189326. [link]