自然言語処理ベンチマークの問題を解くには、条件、手続き、例外などを正しく扱うことが必要となる。従来の考え方では、自然言語の文の意味を形式言語により表現し、証明としてタスクの解を求めることが目指されてきた。しかし、今日のタスクでは、暗黙の前提や外部知識も必要となり、完全な意味表現を大規模に構築することは、実用上困難である。一方で、LLMやCoTなどの解き方では、解を得る推論過程を厳密に検査・分析することができない。 本研究では、この問いに対して、自然言語のタスクをプログラムに変換して解くことを提案する。自然言語のテキストを、プログラムに変換して実行可能な表現を抽出し、事前知識をRAGとして組み合わせて反復的に改良する。 数学的推論、多段階推論、因果推論、ならびに規則や例外を多く含む法律・バイオメディカル分野のベンチマークにおいて、本手法は、テキストのみの推論および単発のコード実行を一貫して上回る性能を示した。本研究はベンチマークを解く上で必要となる条件や例外を実行可能な形式として明示化することで、証明志向の意味論と純粋なテキスト推論との間をつなぐ実用的な橋渡しを実現している。 参考文献 Haoyang Chen and Kumiko Tanaka-Ishii. Understanding Benchmark Language Under Weakened Formal Semantics. Transactions of the Association for Computational Linguistics (TACL), in…
機械学習
14 Articles
14
本研究は、テキスト中の重複部分列に基づき、自然言語とLLMの差を考えるものである。長さm重複の数Dmは、高次 Rényi エントロピーと解析的に関連付けることができる。高次エントロピーを利用した解析結果では、人間の文書では、重複の情報量の、重複長mに対する増大は非常に遅く、事前情報に入念な参照構造を打ち立てて文書が進む性質を持っていることが浮き彫りになる。一方、LLMが生成するテキストでは、情報量の増大は人間のそれよりも速い。LLMの生成メカニズムがこの差を生み出している可能性があることが論じられている。 参考文献 Kumiko Tanaka-Ishii. Repeated Sequences Reveal Gaps between Large Language Models and Natural Language. Accepted to the 64th Annual Meeting of the…
ChatGPTをはじめとする大規模言語モデル(LLM)は、メタデータ作成、意味情報の補完、作品解説文の生成など、デジタル・ヒューマニティーズ(DH)分野においても広く活用されている。一方で、AIが生成した記述の品質を評価するとともに、人手で整備されたメタデータが生成結果にどのような影響を与えるのかを検証することが重要である。 本研究では、陶磁器作品を対象とした自動説明文生成について検討する。陶磁器は絵画のような平面的な作品と比較して形状や構造が複雑であり、記述生成が難しい。また、歴史的に広く制作・利用されてきた一方で、記録が不完全な場合も多く、DH研究において重要な対象である。 実験では、11,566件のオープンアクセス収蔵品データからなるRijksmuseumデータセットを用い、LLM(ChatGPT)と、類似作品を検索してそのメタデータを活用する検索拡張生成(RAG)型LLMであるTerraLexを比較した。その結果、RAGを用いた手法(TerraLex)は、事実誤認が少なく、より正確で文脈情報を豊富に含む記述を生成した。また、人間による評価においても一貫して高い評価を得た。これらの結果から、陶磁器作品の記述生成におけるRAGの有効性と、人手で作成された高品質なメタデータの重要性が明らかとなった。 参考文献 Kaoru Shimabayashi and Kumiko Tanaka-Ishii. Retrieval-Augmented Description Generation for Ceramic Artworks — Effectiveness of Knowledge-Enhancement by the Museum Metadata. Accepted to…
モード崩壊は、生成モデリングにおける継続的な課題であり、自己回帰的なテキスト生成においては、明示的なループから、多様性の段階的な喪失、さらには生成軌道の早期収束に至るまで、さまざまな形で現れる。本研究では、力学系の観点からこの現象を捉え直し、モード崩壊を、幾何学的崩壊によって状態空間の到達可能性が低下する現象として再解釈する。すなわち、生成の過程で、モデルの内部軌道が表現空間内の低次元領域に閉じ込められていくという見方である。 この見方は、モード崩壊が単なるトークンレベルの現象ではなく、記号的制約や確率のみに基づくデコーディング・ヒューリスティックだけでは安定的に解決できないことを示唆している。この観点に基づき、本研究では Reinforced Mode Regulation(RMR)を提案する。RMR は、Transformer の value cache における支配的な自己強化方向を制御する、軽量かつオンラインな状態空間介入手法であり、低ランク減衰として実装される。複数の大規模言語モデルを用いた実験において、RMR はモード崩壊を大幅に抑制し、標準的なデコーディングでは通常 2.0 nats/step 付近で崩壊が生じるのに対し、0.8 nats/step という極めて低いエントロピー率でも、安定した高品質な生成を可能にすることを示した。 参考文献 Du, X., and Tanaka-Ishii, K. Escaping Mode Collapse…

大規模言語モデル(LLM)は自然言語生成において顕著な進歩を遂げている一方で、パープレキシティが低い場合であっても、反復や文のちぐはぐさといった不可解な挙動を依然として示す。このことは、局所的な予測精度を重視するあまり長距離の構造的複雑さを見落としてしまうという、従来の評価指標の本質的な限界を浮き彫りにしている。本研究では、自己相似性を測るフラクタル幾何学的な尺度である「相関次元」を導入し、言語モデルの観点から知覚されるテキストの認識論的複雑さを定量化する。この指標は、言語の階層的な再帰構造を捉えることで、局所的および大域的な性質を統一的な枠組みのもとで橋渡しする役割を果たす。大規模な実験を通じて、相関次元が (1) 事前学習過程における3つの異なるフェーズを明らかにし、(2) 文脈依存的な複雑さを反映し、(3) モデルのハルシネーション傾向を示唆し、さらに (4) 生成テキストに現れる複数のデジェネレーション形態を高い信頼性で検出できることを示す。我々の手法は計算効率に優れ、4ビット精度までのモデル量子化に対しても頑健であり、Transformer や Mamba をはじめとする広範な自回帰アーキテクチャに適用可能である。また、LLM の生成ダイナミクスに対して新たな洞察を提供する。 参考文献 Du, X., & Tanaka-Ishii, K. Correlation Dimension of Autoregressive Large Language Models. In The…
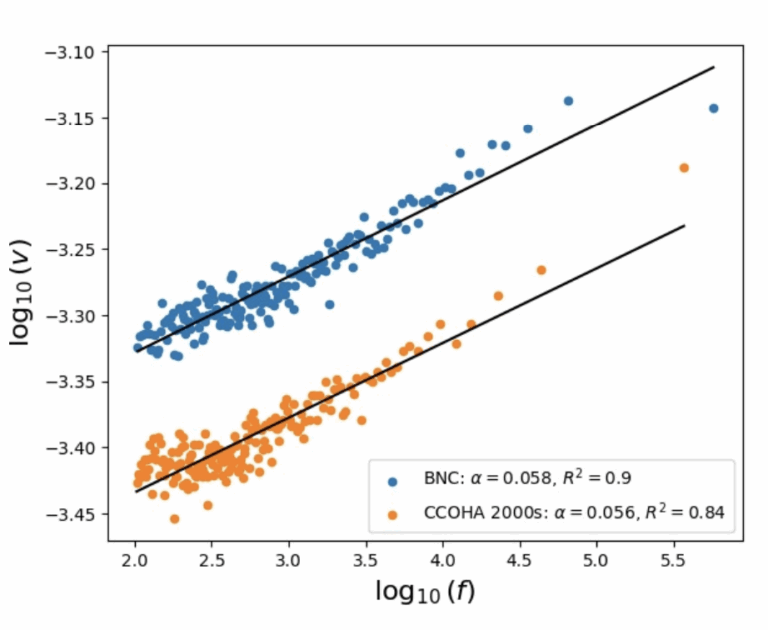
語の出現頻度と語義数のあいだには冪乗則が成り立つことをZipfが報告しており、「Zipf の意味頻度則」として知られます。これはいわゆるZipf則とは別の法則です。従来、語義数は辞書中の意味の数で計測されていましたが、すると、辞書に登録のない単語について、意味頻度則を調べることができません。本研究では、言語モデル(LM)から得られる単語ベクトルのばらつきを計測し、それと頻度の間に冪乗則が成り立つことを示しました。この冪乗則は、ある程度大きな言語モデルでないと観測されないことも報告しています。甲南大学・永田亮先生と共同研究の成果です。 参考文献 Nagata, R., & Tanaka-Ishii, K. (2025, July). A New Formulation of Zipf’s Meaning-Frequency Law through Contextual Diversity. In Proceedings of the 63rd…
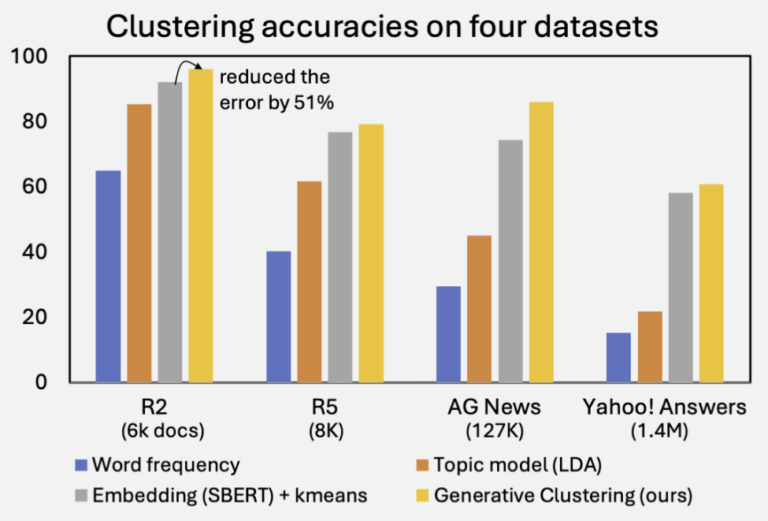
クラスタリングは、機械学習やデータマイニングにおける基本的な技術であり、現実世界における自己組織化パターンを理解するための強力な手段です。 その本質は情報理論的であり、ドキュメント集合に対して「いくつクラスタが存在し、各ドキュメントはどのクラスタに属するか」という最も単純な仮説を立て、それに基づいて情報の損失を最小化することにあります。 しかしこの10年間で、情報理論的な観点に基づかないクラスタリング手法が主流となってきました。ドキュメントを単語の出現確率分布として表す代わりに、BERTのような強力な言語モデルによって密なベクトルとして表現する手法が一般化したためです。これらの埋め込みベースの手法は効果的ですが、自然な確率的解釈が難しく、情報理論の視点は次第に薄れていきました。 本研究では、生成言語モデルを活用することで、この古典的な情報理論的アプローチを再興します。 特に、Doc2Queryモデルを用いて、各ドキュメントを「生成されるテキストの確率分布」として表現します。この生成空間は離散かつ無限ですが、正則化付き重要サンプリング(Regularized Importance Sampling) により、その分布とKLダイバージェンスを高精度に推定します。 つまり、私たちの手法はクラスタリングと統計推定を一体として行います。実験では、4つの標準的なクラスタリングデータセットにおいて、従来の埋め込みベースの強力な手法を大きく上回る性能を達成しました。 参考文献
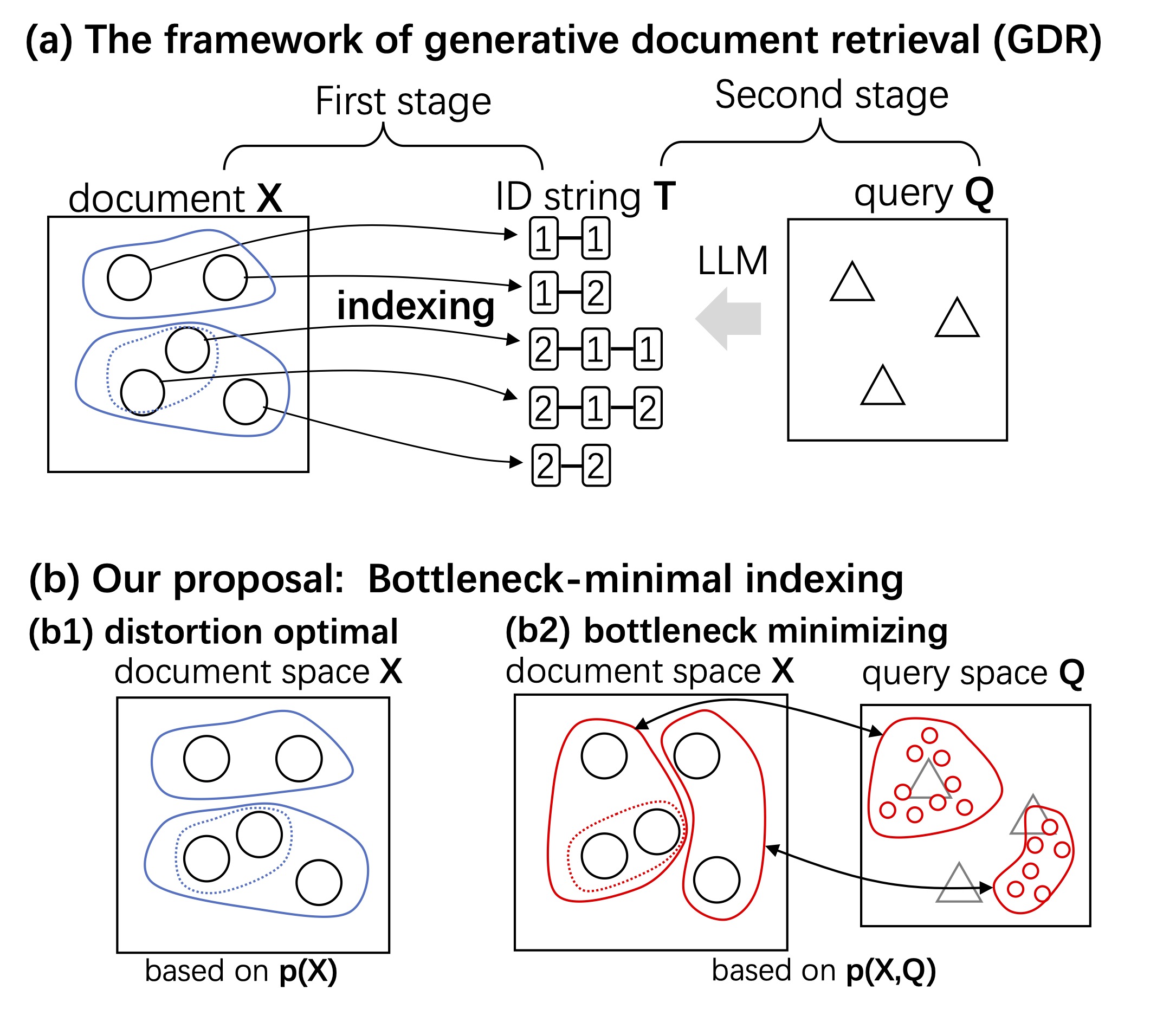
情報理論の視点から生成的文書検索(GDR)を再考し、新しい文書の索引を提案しています。文書をx∈X 、索引をt∈T 、検索クエリq∈Qとする時、GDRでは Q を T にマッピングするようにニューラルネットワークを訓練します。GDRは、文書 X からクエリ Q へ、索引 T を介して、より多くのビットを伝送する系とみなすことができます。シャノンのレート歪み理論を適用することにより、GDRにおける情報伝達ボトルネックを小さくする索引 T を設計することができます。 参考文献
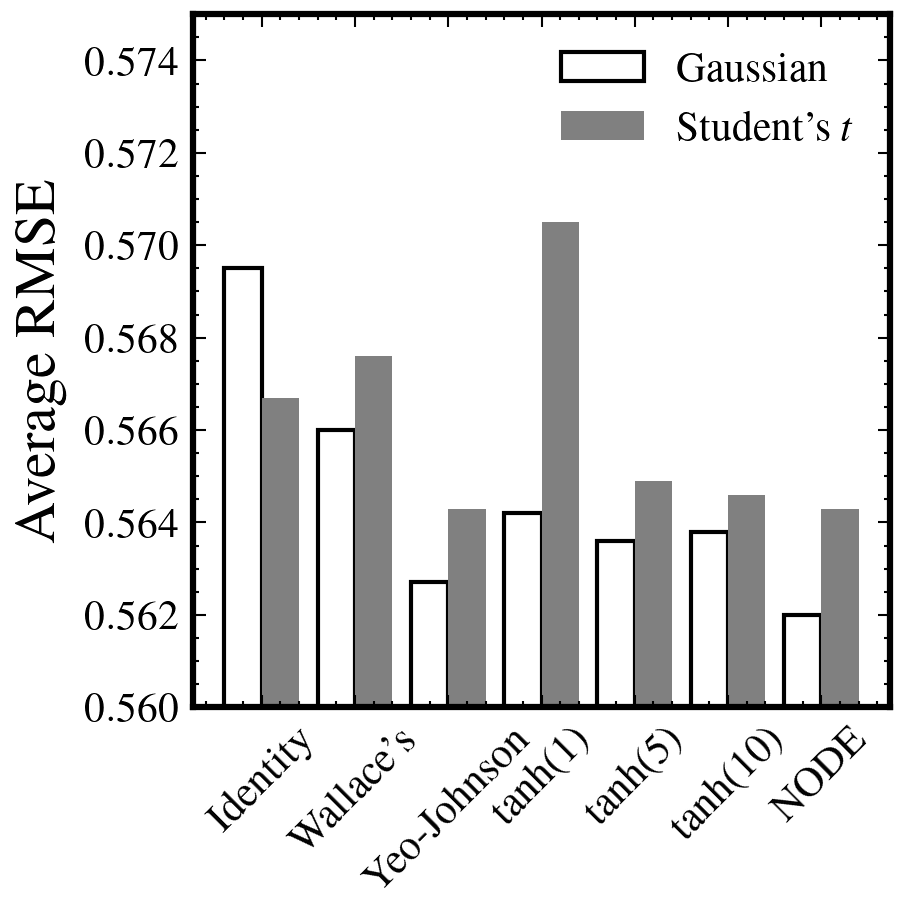
この研究では、実現ボラティリティ(RV)の予測のために、正規化フローを使用した新しい機械学習モデルが提案されています。RVの特性を考慮し、変換と予測モデルを共同でトレーニングする方法が提案され、最大尤度目的関数に基づくトレーニングが行われます。この新しいアプローチは、100銘柄のデータセットにおいて、従来の分析的またはニューラルネットワークに基づく変換方法よりも優れた結果を示しています。 参考文献
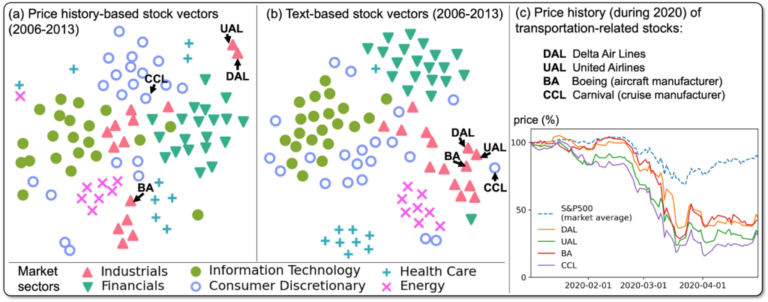
物理経済の理論下では、価格のスケーリング則が知られ、それは市場がなぜ簡単に破綻するのか、 その理由を説明するものです。金融市場の大きな問題の一つは、稀少な事象に起因するリスクの特徴を、 いかに捉えるか、という点にあります。たとえば、コロナ禍は稀少な事象例で、その際の株価の動向は、 過去のデータからモデル化することは難しいのです。この点、新聞などの文書では、 稀な事象を、より強調して記述するものです。このため、価格に加え文書を利用することは、リスクを捉える一つの手段となります。 研究室では、文書データを用いて、経済リスクを計量し応用する方法を研究しています。 参考文献