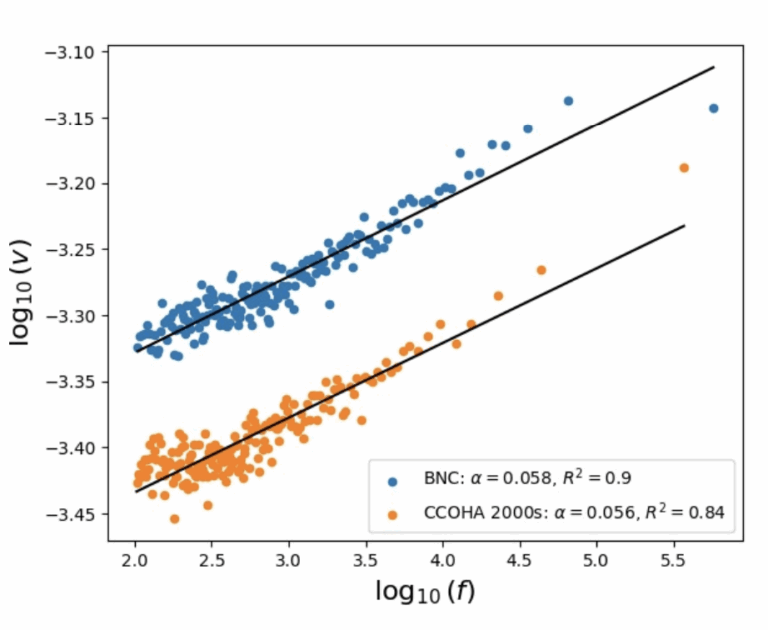
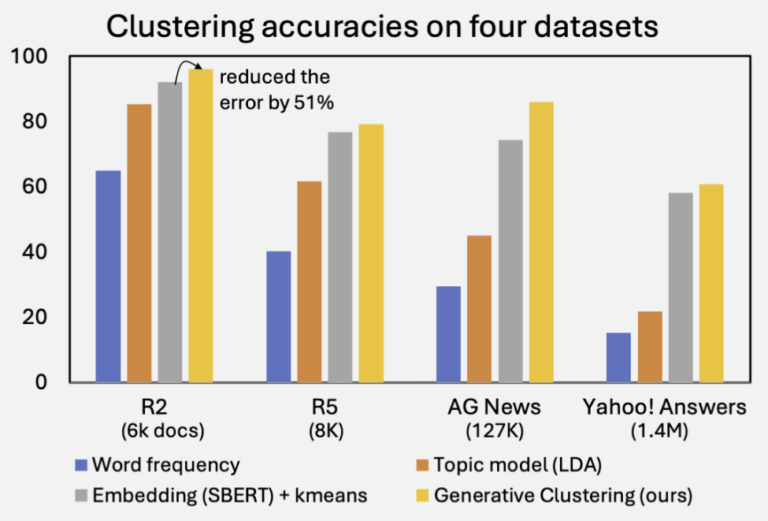
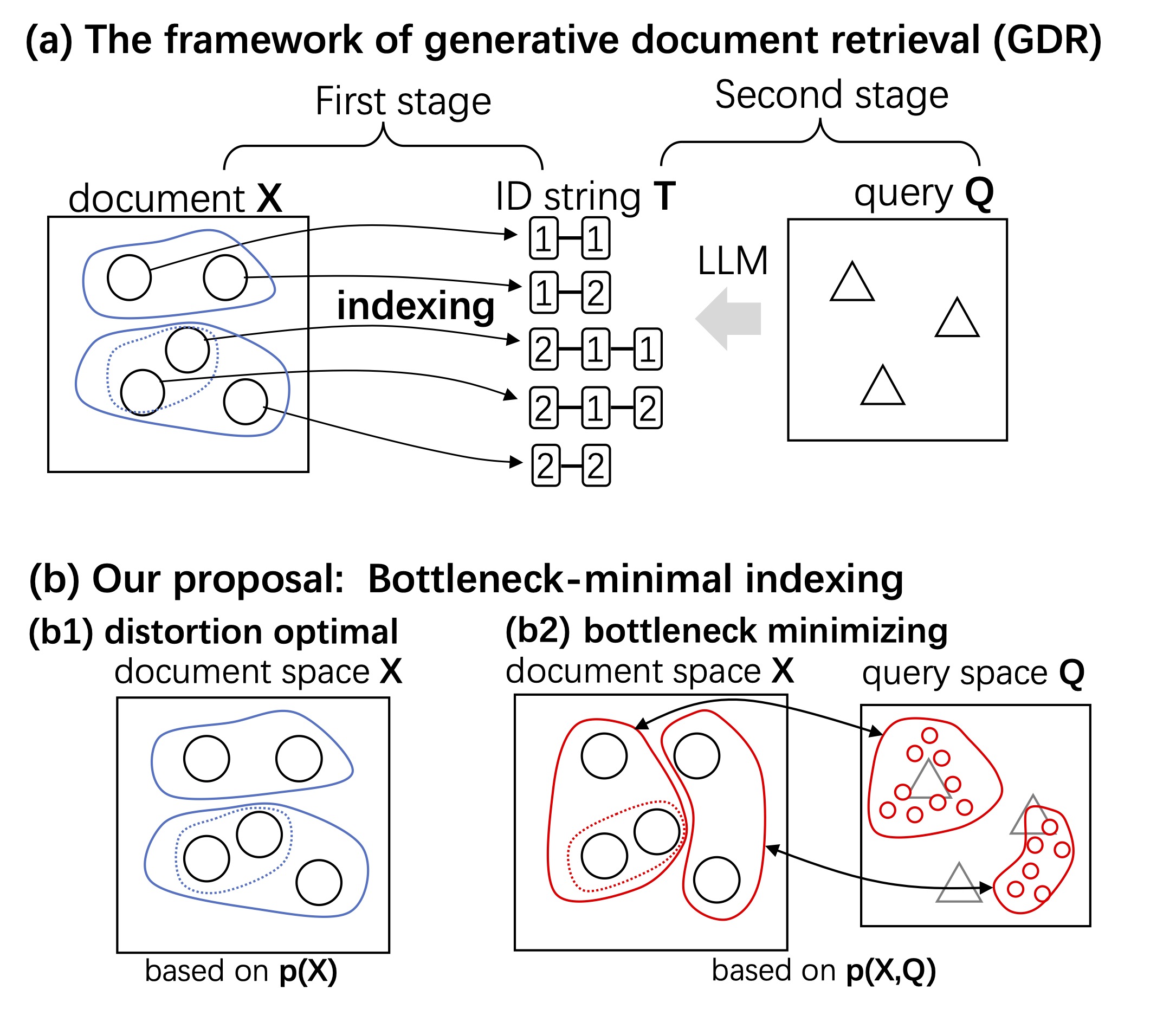
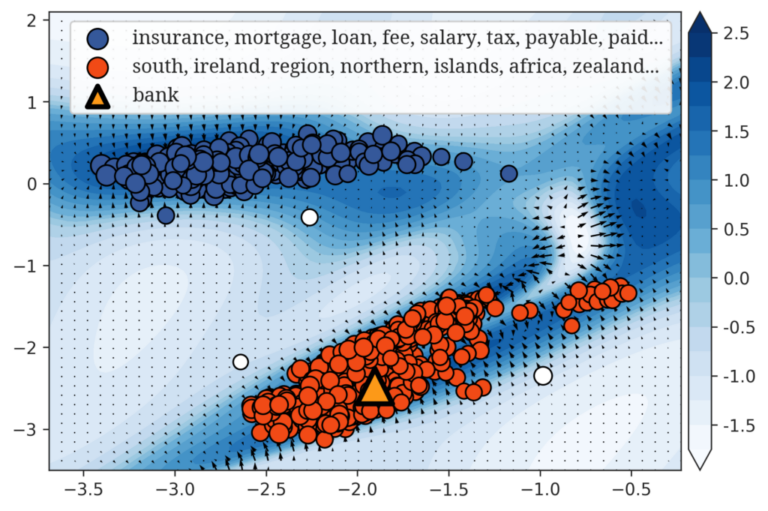
自然言語処理ベンチマークの問題を解くには、条件、手続き、例外などを正しく扱うことが必要となる。従来の考え方では、自然言語の文の意味を形式言語により表現し、証明としてタスクの解を求めることが目指されてきた。しかし、今日のタスクでは、暗黙の前提や外部知識も必要となり、完全な意味表現を大規模に構築することは、実用上困難である。一方で、LLMやCoTなどの解き方では、解を得る推論過程を厳密に検査・分析することができない。 本研究では、この問いに対して、自然言語のタスクをプログラムに変換して解くことを提案する。自然言語のテキストを、プログラムに変換して実行可能な表現を抽出し、事前知識をRAGとして組み合わせて反復的に改良する。 数学的推論、多段階推論、因果推論、ならびに規則や例外を多く含む法律・バイオメディカル分野のベンチマークにおいて、本手法は、テキストのみの推論および単発のコード実行を一貫して上回る性能を示した。本研究はベンチマークを解く上で必要となる条件や例外を実行可能な形式として明示化することで、証明志向の意味論と純粋なテキスト推論との間をつなぐ実用的な橋渡しを実現している。 参考文献 Haoyang Chen and Kumiko Tanaka-Ishii. Understanding Benchmark Language Under Weakened Formal Semantics. Transactions of the Association for Computational Linguistics (TACL), in…
複雑系としての自然言語の数理と機械学習
自然言語を複雑系と捉え、言語データに内在する大域的性質ならびにその言語構造との関係を、フラクタルやカオスの視点から基礎的に研究しています。言語の数理構造をふまえ、言語の数理モデルを構築し、自然言語処理に応用しています。
複雑系としての言語の大域的特性は、金融やコミュニケーションネットワークなど社会的複雑系に共通する性質でもあります。この共通性を生かし、社会的複雑系の大規模な解析や予測を、言語的な視点から行っています。

言語の複雑系科学・数理的性質
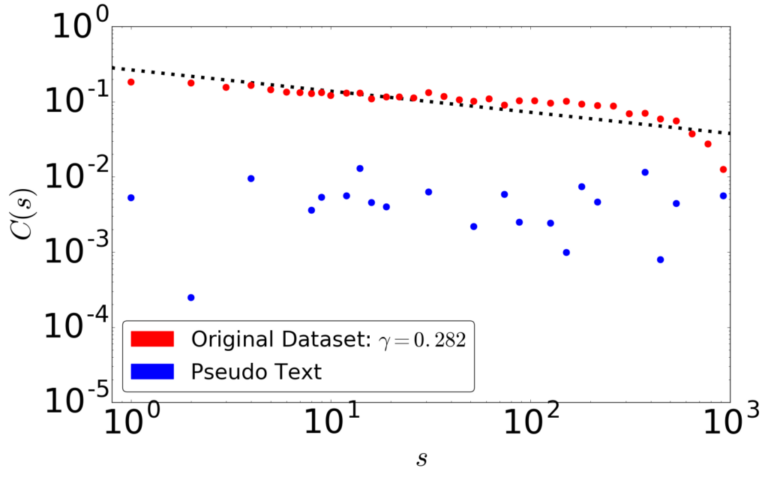
- 言語の非定常特性・長期記憶の計測
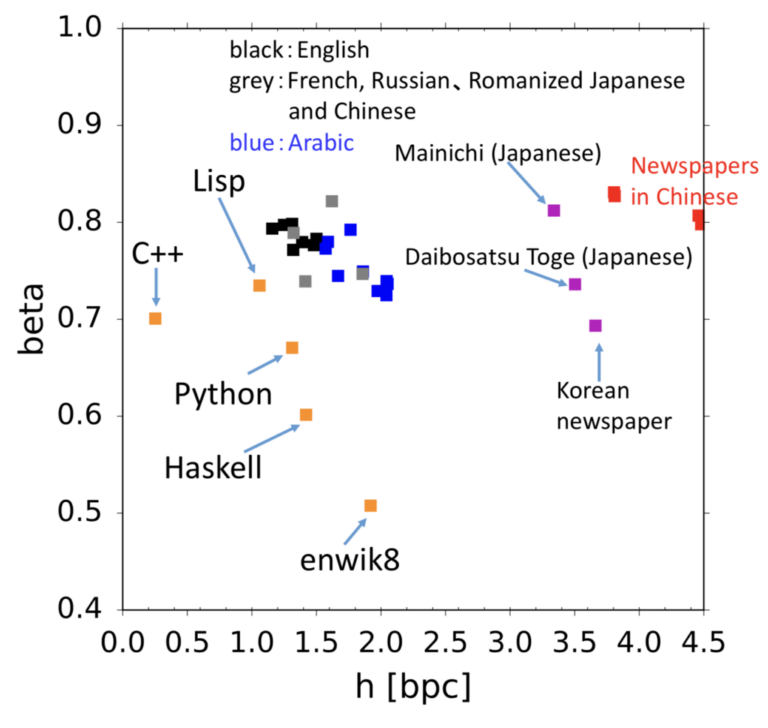
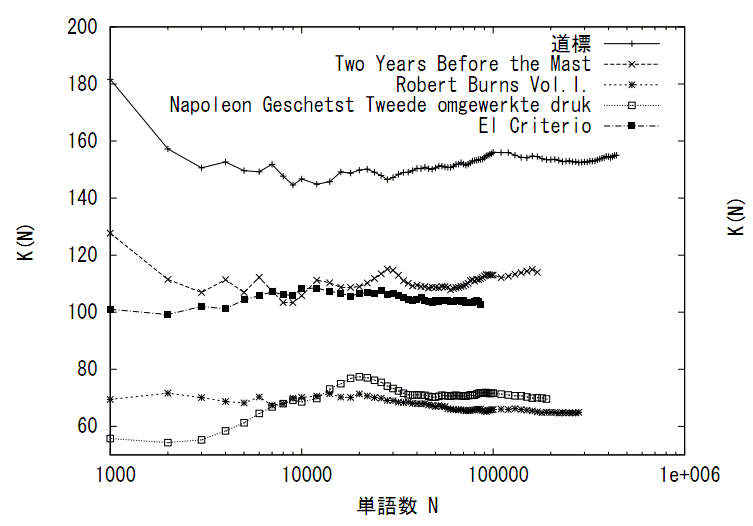
- 言語の系のスケーリング則
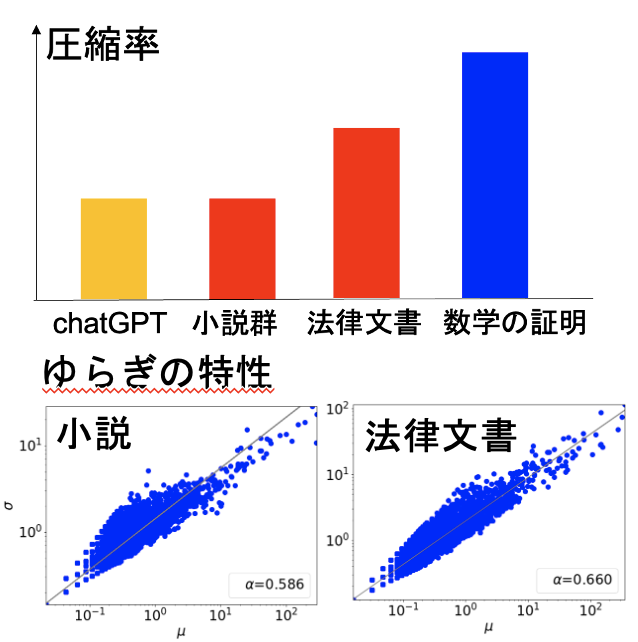
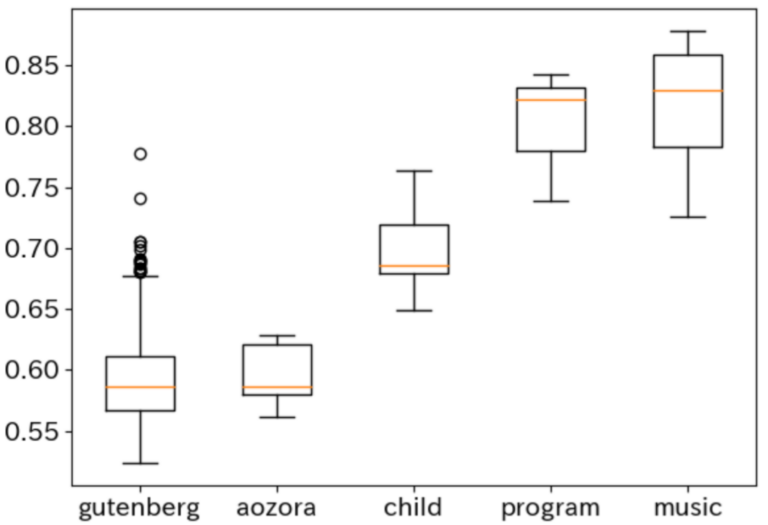
- 言語の複雑さの計測
- 文書・文構造の数理
機械学習に基づく言語の数理モデル
- 言語の統計的性質を再現する数理モデル
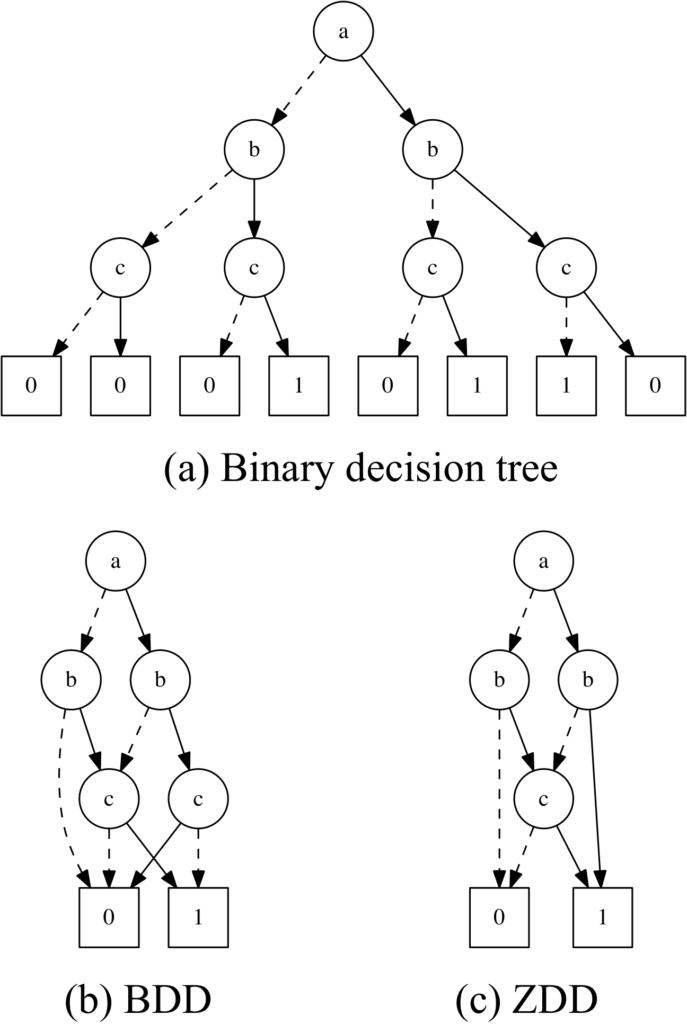
- 埋め込み表現手法
- 長期記憶と生成モデル
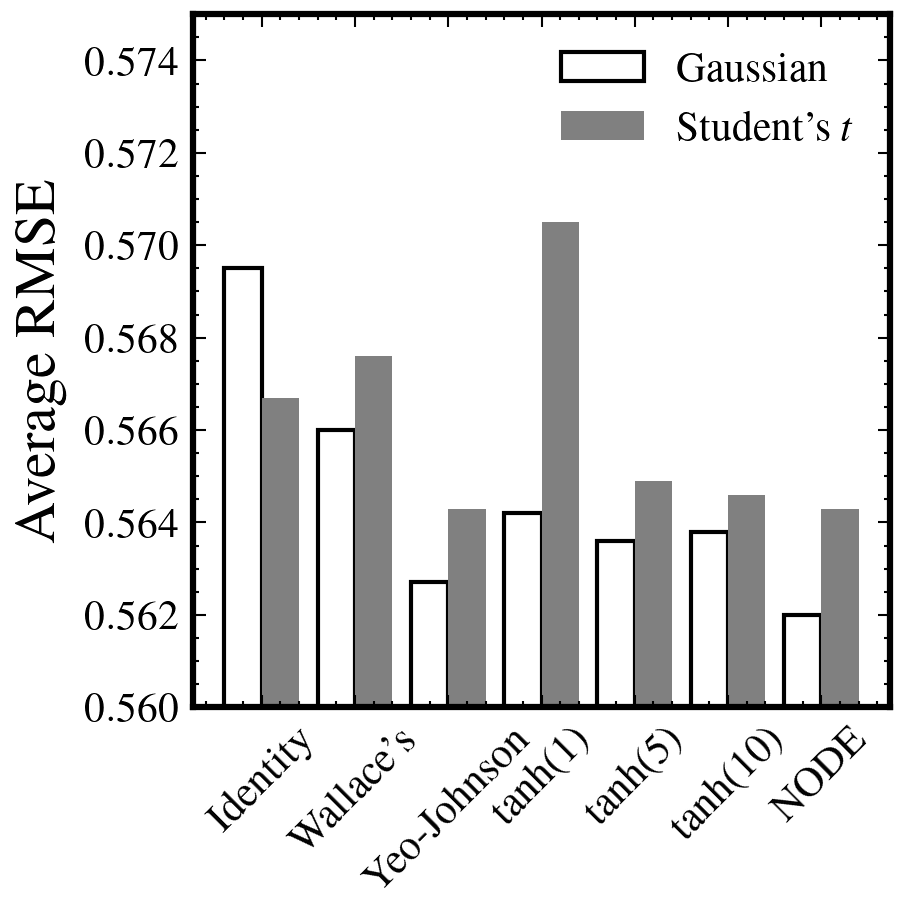
- 複雑系の性質を持つ系列の機械学習手法
- 言語モデルと文書検索の融合
言語的視点からの社会的複雑系の工学
- 社会的対象の埋め込み表現獲得手法
- 法律の複雑系科学と機械学習応用
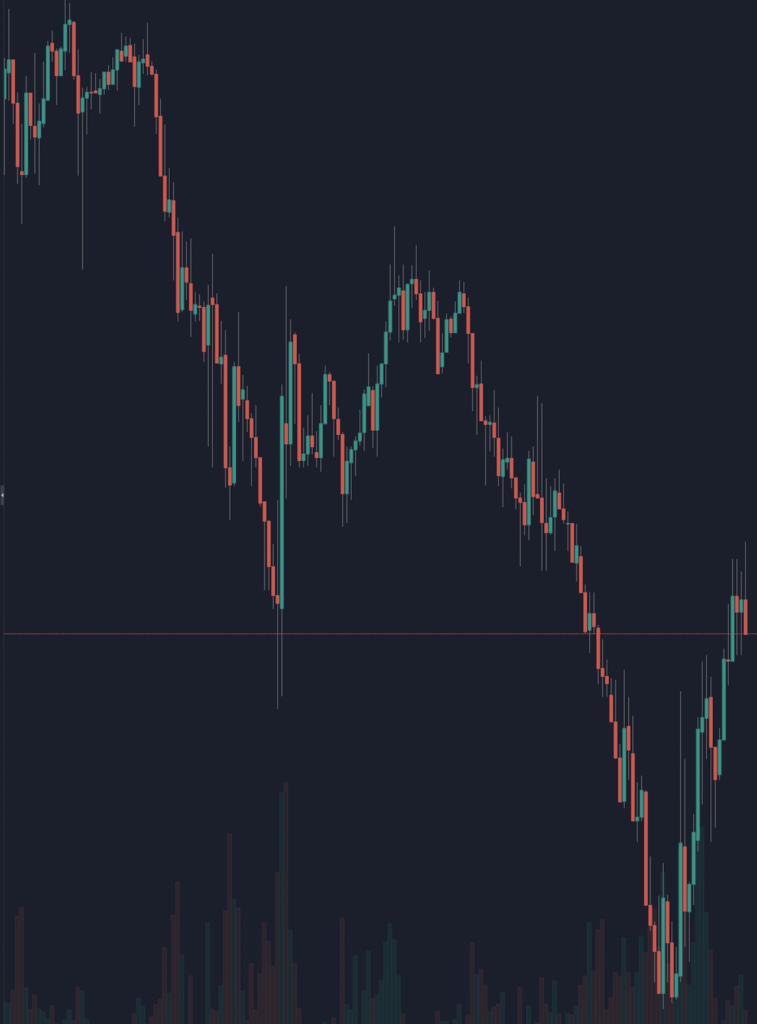
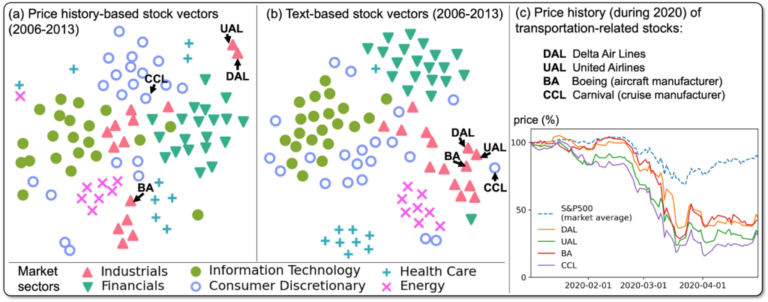
- 言語データに基づく金融データの深層学習
- 推論に基づく言語対象の工学