
Strahler数はもともと川の分岐の複雑さを特徴付けるために提案され、計算木などに応用されてきました。この研究では、Strahler数を自然言語の文の木構造の複雑さを計測するために適用しました。自然言語の文のStrahler数の上限と下限が、3から4になることがわかりました。この数は、文を処理する際に必要なメモリ領域の数を示し、文の長さに応じて対数的に増加するものです。 参考文献
計算言語学
6 Articles
6
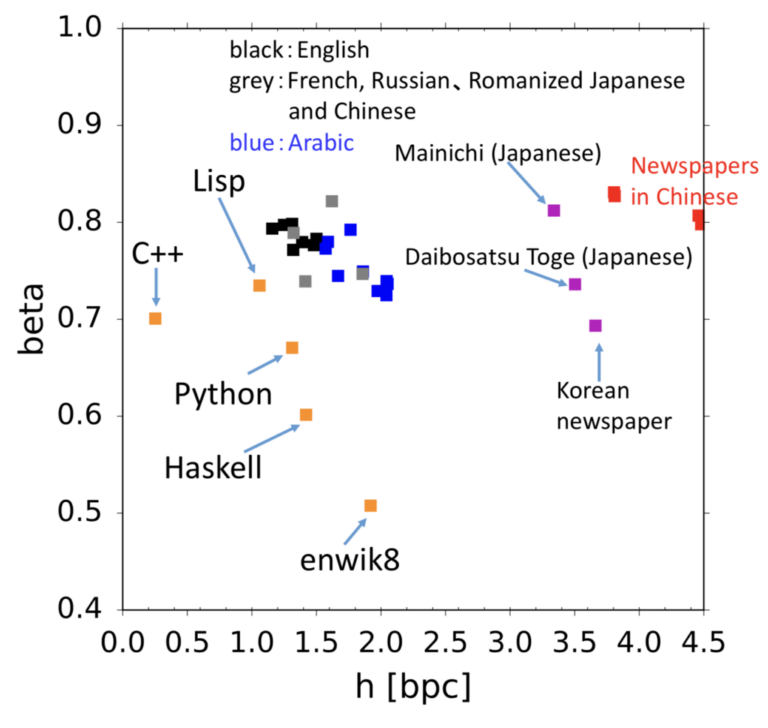
言語、音楽、プログラムなど記号に基づく時系列のエントロピーレートを算出し、 人の記号の時系列に内在する複雑さを探求しています。長さnの時系列の場合の数を、パラメータhを用いて2hnとして考えてみます。まずランダムなビット列の場合はh=1です。では英語を仮に27文字と考えたとしてその数は27n、にはなりません。なぜなら自然言語の場合、qの後にはuしか続かないなど言語的な制約がさまざまにあるからです。情報理論の父シャノンはh=1.3と算出していますが、hの推定は難しい問題で、自然言語のhが正なのかすら未だにわかっていません。研究室では自然言語に加え、音楽・プログラム・金融データなどさまざまな記号時系列の複雑さを推定する研究を行っています。 参考文献

複雑系の本質的な一面として、イベントが「塊として現れる性質」があります。たとえば、下図は、ある特定の単語群が時系列の中で現れる位置を示しており、上段ほど「稀」な単語に絞って表示しています。最上段を見ると、稀なイベントが塊として現れていることがわかります。統計物理学では、このような性質をゆらぎ解析や長相関として捉える方法論が研究されてきましたが、それは主として数値時系列に対する解析手法となっており、非数値的な時系列での計測方法は確立したとはいえません。研究室では、既存手法を改良し、安定してこのようなゆらぎを計測する方法を模索しています。得られた方法を利用し、系の複雑さを計量することも試みています。 参考文献
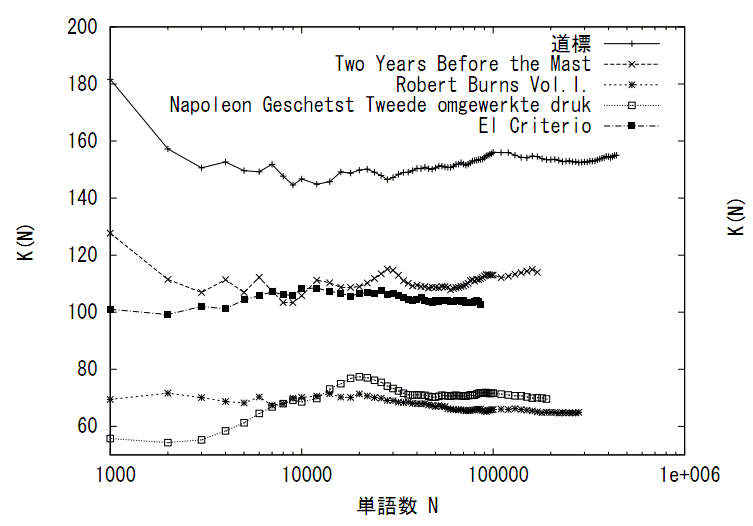
様々な種類のデータに対して様々な統計量が数理的に考察されてきました。自然言語のテキストに対しては著者や言語種、ジャンルなど、その種類を量的に峻別する統計量とは何かが考えられてきました。例えば統計学者Yuleが提案したKがその一つで、これはRenyiの2次エントロピーと等価です。YuleのKはデータ量に依存しない統計量となっており、データの性質を安定的に表す統計量となっています。研究室では、データのスケーリング則との関連をふまえ、このような統計量として何があるかを探究しています。 参考文献
生成モデルは、工学上の一つ重要なテーマで、ある系のサンプルを、擬似的に実現する方式のことです。生成モデルを探求することは、系の本質を捉え、それを実現する学習器の能力を吟味し、その構成を再考することにつながります。研究室では、マルコフモデル、文法的モデル、Simon生成過程など既存のモデルに加え、複雑系ネットワーク上のランダムウォーク、AutoencoderやAdversarialなど深層学習生成モデルも含め、複雑系を包括的に再現する試みを行っています。 参考文献
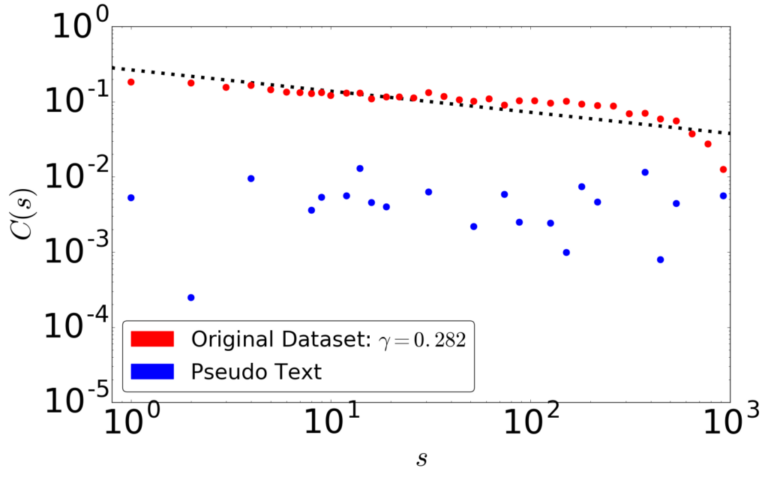
深層学習はデータのどのような側面を捉え、または捉えきれないのでしょうか。 複雑系としての記号の系にはさまざまな経験則が成り立つことが知られています。 研究室では、深層学習が生成する擬似データにどの程度の冪乗則が成り立っているか検証し、 従来の観点からは異なる観点から深層学習を吟味し、深層学習の改良につなげることを考えています。 たとえば右図は、文書は成り立つ長相関が文字レベル深層言語モデルでは成立しないことを示しています。 このような議論は自然言語以外の系、例えば金融市場にも適用することができます。 参考文献