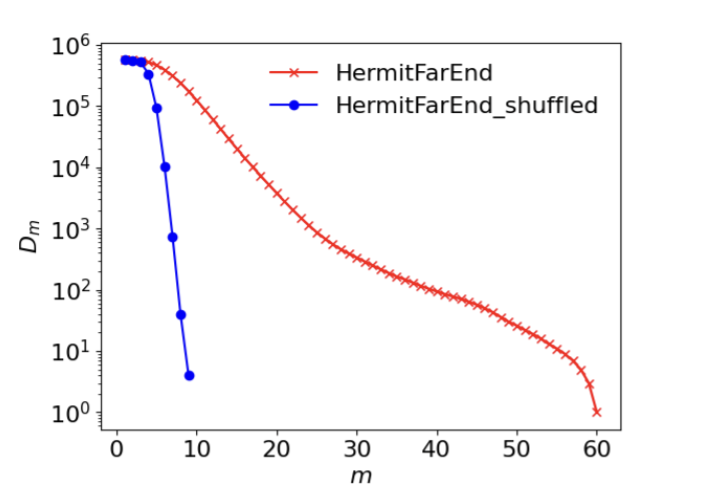
本研究は、テキスト中の重複部分列に基づき、自然言語とLLMの差を考えるものである。長さm重複の数Dmは、高次 Rényi エントロピーと解析的に関連付けることができる。高次エントロピーを利用した解析結果では、人間の文書では、重複の情報量の、重複長mに対する増大は非常に遅く、事前情報に入念な参照構造を打ち立てて文書が進む性質を持っていることが浮き彫りになる。一方、LLMが生成するテキストでは、情報量の増大は人間のそれよりも速い。LLMの生成メカニズムがこの差を生み出している可能性があることが論じられている。
参考文献
Kumiko Tanaka-Ishii. Repeated Sequences Reveal Gaps between Large Language Models and Natural Language. Accepted to the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026), to appear in July 2026.