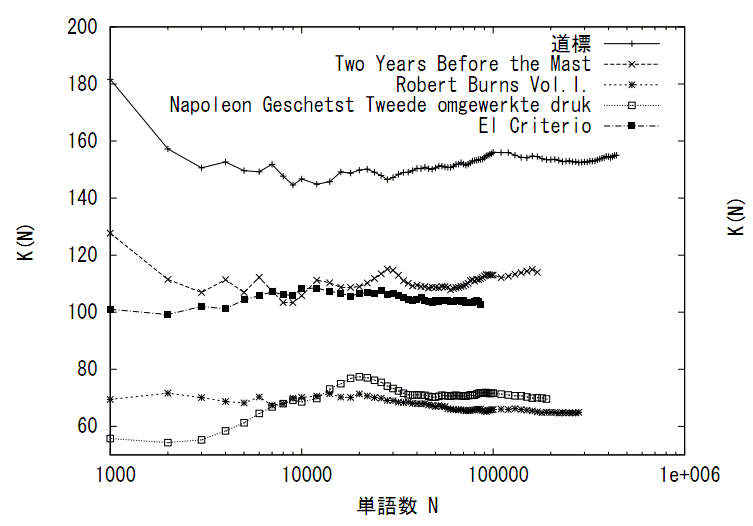
様々な種類のデータに対して様々な統計量が数理的に考察されてきました。自然言語のテキストに対しては著者や言語種、ジャンルなど、その種類を量的に峻別する統計量とは何かが考えられてきました。例えば統計学者Yuleが提案したKがその一つで、これはRenyiの2次エントロピーと等価です。YuleのKはデータ量に依存しない統計量となっており、データの性質を安定的に表す統計量となっています。研究室では、データのスケーリング則との関連をふまえ、このような統計量として何があるかを探究しています。 参考文献
Yule’s K
1 Article
1