
自然言語の相関次元は、大規模言語モデルによって生成された高次元ベクトル
列にGrassberger-Procacciaアルゴリズムを適用することで測定されます。こ
の方法は、以前はユークリッド空間でのみ研究されていましたが、本研究では、
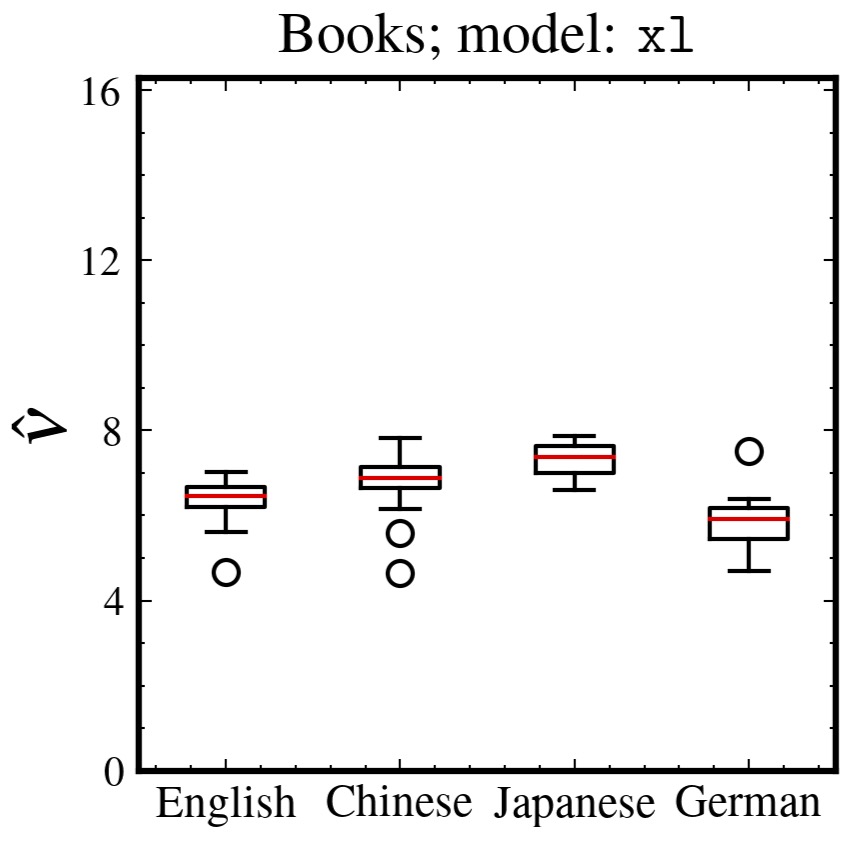
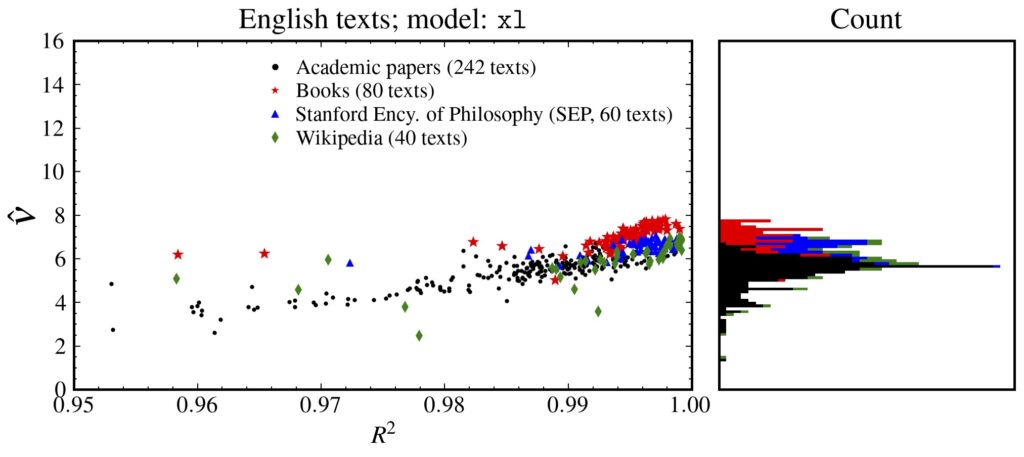
統計多様体上にFisher-Rao距離を用いて再定式化しました。相関次元は、普遍
的に約6.5であることがわかりました。この値は単純な離散ランダム列の
それよりも小さく、Barabási-Albert過程のそれよりも大きいです。



参考文献
- Xin Du and Kumiko Tanaka-Ishii. Correlation dimension of natural language in a statistical manifold. Physical Review Research 6, L022028, 2024. [link]