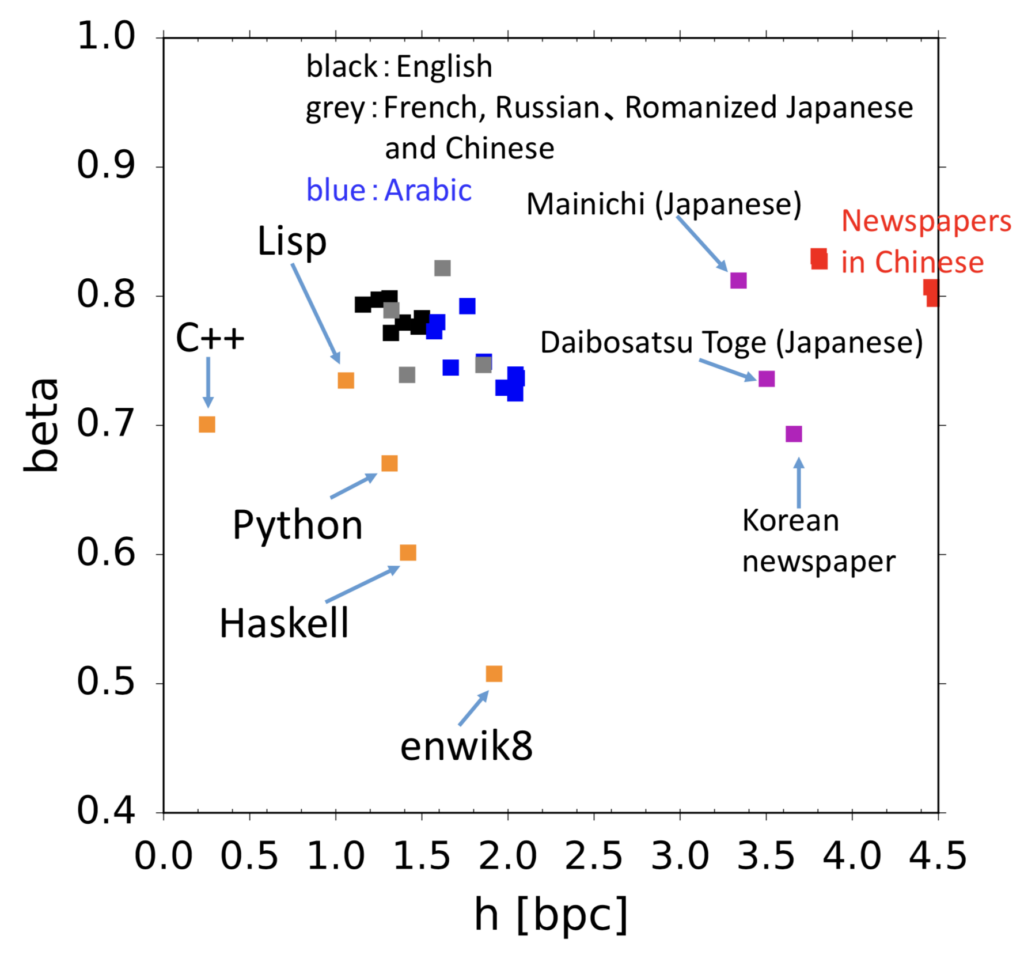
言語、音楽、プログラムなど記号に基づく時系列のエントロピーレートを算出し、 人の記号の時系列に内在する複雑さを探求しています。長さnの時系列の場合の数を、パラメータhを用いて2hnとして考えてみます。まずランダムなビット列の場合はh=1です。では英語を仮に27文字と考えたとしてその数は27n、にはなりません。なぜなら自然言語の場合、qの後にはuしか続かないなど言語的な制約がさまざまにあるからです。情報理論の父シャノンはh=1.3と算出していますが、hの推定は難しい問題で、自然言語のhが正なのかすら未だにわかっていません。研究室では自然言語に加え、音楽・プログラム・金融データなどさまざまな記号時系列の複雑さを推定する研究を行っています。
参考文献
- Ryosuke Takahira, Kumiko Tanaka-Ishii, and Łukasz Dębowski. Entropy Rate Estimates for Natural Language—A New Extrapolation of Compressed Large-Scale Corpora. Entropy, 2016. [paper]
- Geng Ren, Shuntaro Takahashi, Kumiko Tanaka-Ishii. Entropy Rate Estimation for English via a Large Cognitive Experiment Using Mechanical Turk. Entropy, 2019. [paper]