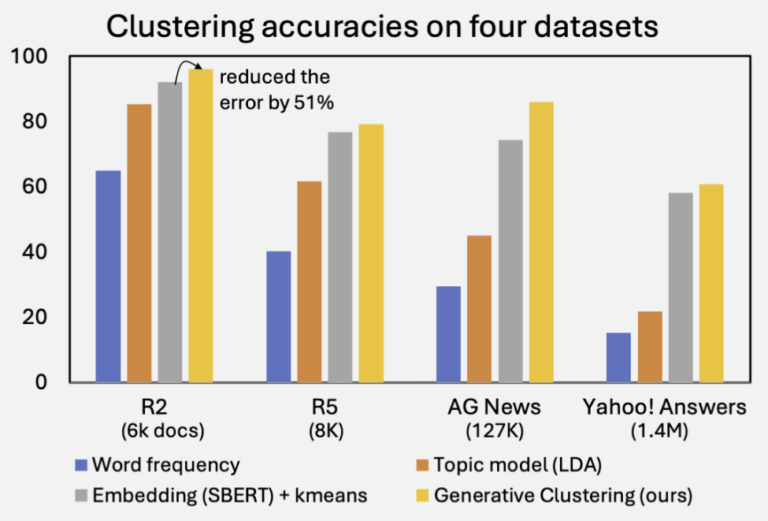
クラスタリングは、機械学習やデータマイニングにおける基本的な技術であり、現実世界における自己組織化パターンを理解するための強力な手段です。 その本質は情報理論的であり、ドキュメント集合に対して「いくつクラスタが存在し、各ドキュメントはどのクラスタに属するか」という最も単純な仮説を立て、それに基づいて情報の損失を最小化することにあります。 しかしこの10年間で、情報理論的な観点に基づかないクラスタリング手法が主流となってきました。ドキュメントを単語の出現確率分布として表す代わりに、BERTのような強力な言語モデルによって密なベクトルとして表現する手法が一般化したためです。これらの埋め込みベースの手法は効果的ですが、自然な確率的解釈が難しく、情報理論の視点は次第に薄れていきました。 本研究では、生成言語モデルを活用することで、この古典的な情報理論的アプローチを再興します。 特に、Doc2Queryモデルを用いて、各ドキュメントを「生成されるテキストの確率分布」として表現します。この生成空間は離散かつ無限ですが、正則化付き重要サンプリング(Regularized Importance Sampling) により、その分布とKLダイバージェンスを高精度に推定します。 つまり、私たちの手法はクラスタリングと統計推定を一体として行います。実験では、4つの標準的なクラスタリングデータセットにおいて、従来の埋め込みベースの強力な手法を大きく上回る性能を達成しました。 参考文献
言語モデル
6 Articles
6

自然言語の相関次元は、大規模言語モデルによって生成された高次元ベクトル列にGrassberger-Procacciaアルゴリズムを適用することで測定されます。この方法は、以前はユークリッド空間でのみ研究されていましたが、本研究では、統計多様体上にFisher-Rao距離を用いて再定式化しました。相関次元は、普遍的に約6.5であることがわかりました。この値は単純な離散ランダム列のそれよりも小さく、Barabási-Albert過程のそれよりも大きいです。 参考文献
2018年初頭のビットコインの暴落の背景には、社会的な要因がさまざまにあり ます。中でも、メディアの影響は大きく、ニュース報道や、TwitterなどのSNS での真偽入れ混じった情報拡散が大影響を与えています。 研究室では、株価や仮想通貨のデータを集積し、ニュースやTwitterが価格変動に与える影響を分析し, 文書の中から価格に影響を与えるであろう情報のマイニングを試みています。 参考文献
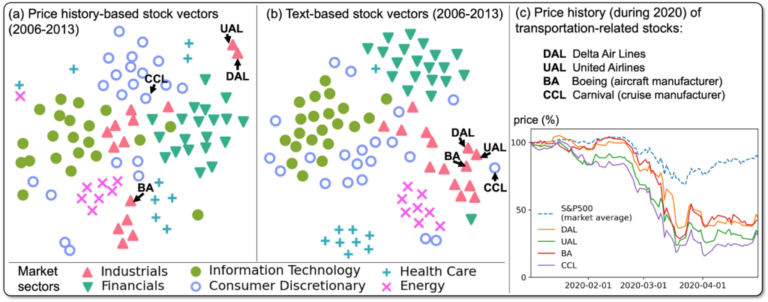
物理経済の理論下では、価格のスケーリング則が知られ、それは市場がなぜ簡単に破綻するのか、 その理由を説明するものです。金融市場の大きな問題の一つは、稀少な事象に起因するリスクの特徴を、 いかに捉えるか、という点にあります。たとえば、コロナ禍は稀少な事象例で、その際の株価の動向は、 過去のデータからモデル化することは難しいのです。この点、新聞などの文書では、 稀な事象を、より強調して記述するものです。このため、価格に加え文書を利用することは、リスクを捉える一つの手段となります。 研究室では、文書データを用いて、経済リスクを計量し応用する方法を研究しています。 参考文献
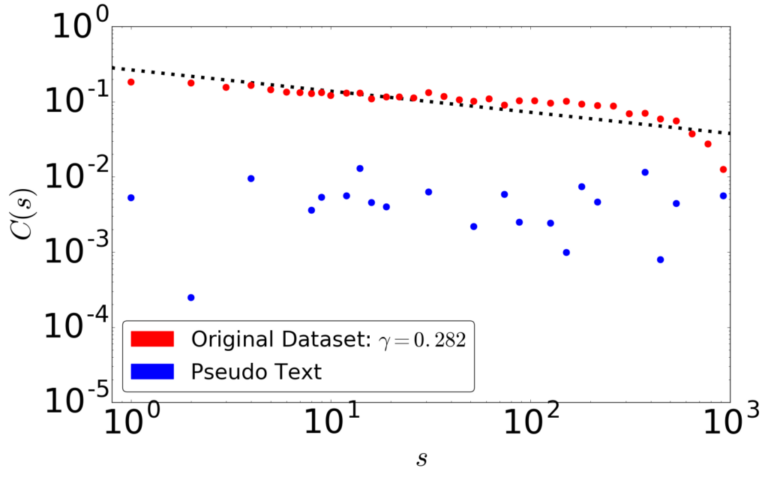
深層学習はデータのどのような側面を捉え、または捉えきれないのでしょうか。 複雑系としての記号の系にはさまざまな経験則が成り立つことが知られています。 研究室では、深層学習が生成する擬似データにどの程度の冪乗則が成り立っているか検証し、 従来の観点からは異なる観点から深層学習を吟味し、深層学習の改良につなげることを考えています。 たとえば右図は、文書は成り立つ長相関が文字レベル深層言語モデルでは成立しないことを示しています。 このような議論は自然言語以外の系、例えば金融市場にも適用することができます。 参考文献
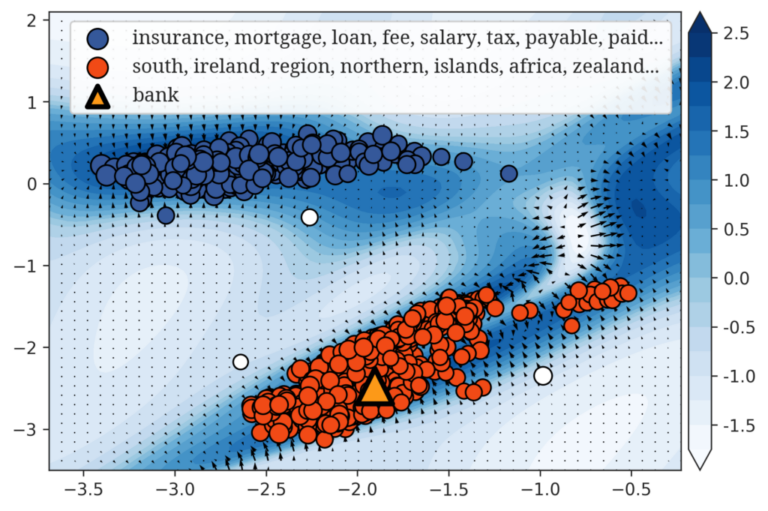
機械学習では単語など文書の要素をベクトルとして表現しなければならず、それを埋め込み表現といいます。 現在の埋め込み表現は、線形ベクトル空間の中に単語をベクトルとして表現しますが、線形空間では、 多義性など単語の持つ非線形な特性を表現することができません。 このため、既存のベクトル表現に代わる数理的な表現を研究しています。 試みとして、FIRE という関数に基づく表現を構築しました。FIREはBERTと同等の性能を有し、単語の意味の数の推定することにおいては、BERTよりも優れている埋め込み表現です。 参考文献