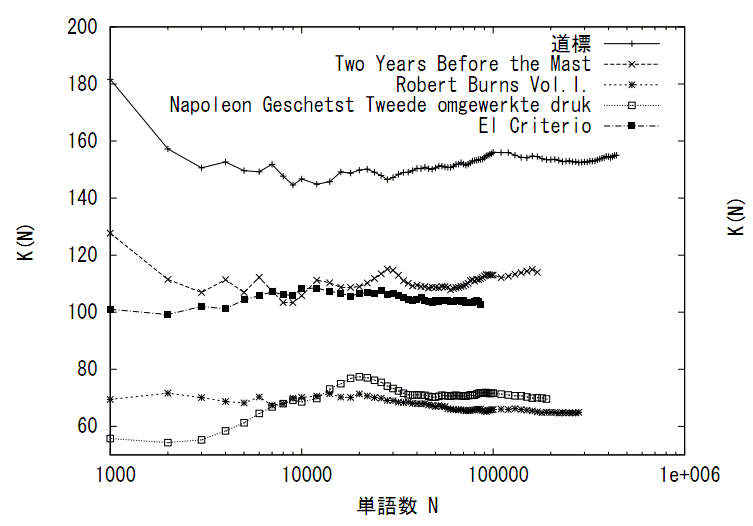
様々な種類のデータに対して様々な統計量が数理的に考察されてきました。自然言語のテキストに対しては著者や言語種、ジャンルなど、その種類を量的に峻別する統計量とは何かが考えられてきました。例えば統計学者Yuleが提案したKがその一つで、これはRenyiの2次エントロピーと等価です。YuleのKはデータ量に依存しない統計量となっており、データの性質を安定的に表す統計量となっています。研究室では、データのスケーリング則との関連をふまえ、このような統計量として何があるかを探究しています。 参考文献
スケール則
2 Articles
2
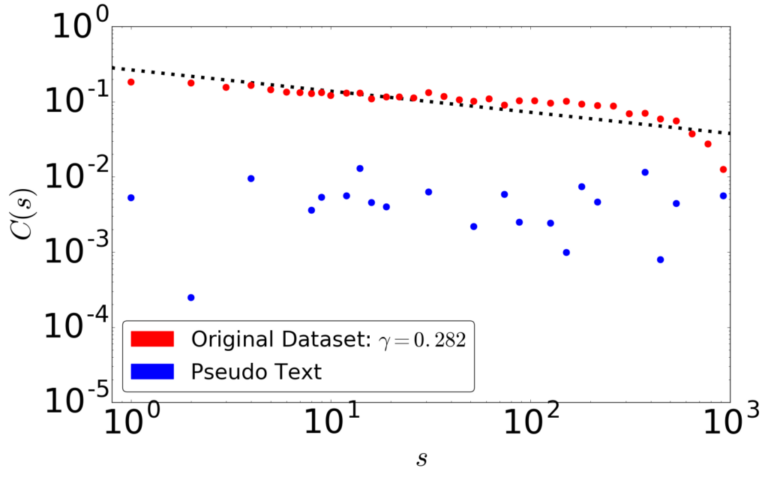
深層学習はデータのどのような側面を捉え、または捉えきれないのでしょうか。 複雑系としての記号の系にはさまざまな経験則が成り立つことが知られています。 研究室では、深層学習が生成する擬似データにどの程度の冪乗則が成り立っているか検証し、 従来の観点からは異なる観点から深層学習を吟味し、深層学習の改良につなげることを考えています。 たとえば右図は、文書は成り立つ長相関が文字レベル深層言語モデルでは成立しないことを示しています。 このような議論は自然言語以外の系、例えば金融市場にも適用することができます。 参考文献