クラスタリングは、機械学習やデータマイニングにおける基本的な技術であり、現実世界における自己組織化パターンを理解するための強力な手段です。 その本質は情報理論的であり、ドキュメント集合に対して「いくつクラスタが存在し、各ドキュメントはどのクラスタに属するか」という最も単純な仮説を立て、それに基づいて情報の損失を最小化することにあります。
しかしこの10年間で、情報理論的な観点に基づかないクラスタリング手法が主流となってきました。ドキュメントを単語の出現確率分布として表す代わりに、BERTのような強力な言語モデルによって密なベクトルとして表現する手法が一般化したためです。これらの埋め込みベースの手法は効果的ですが、自然な確率的解釈が難しく、情報理論の視点は次第に薄れていきました。
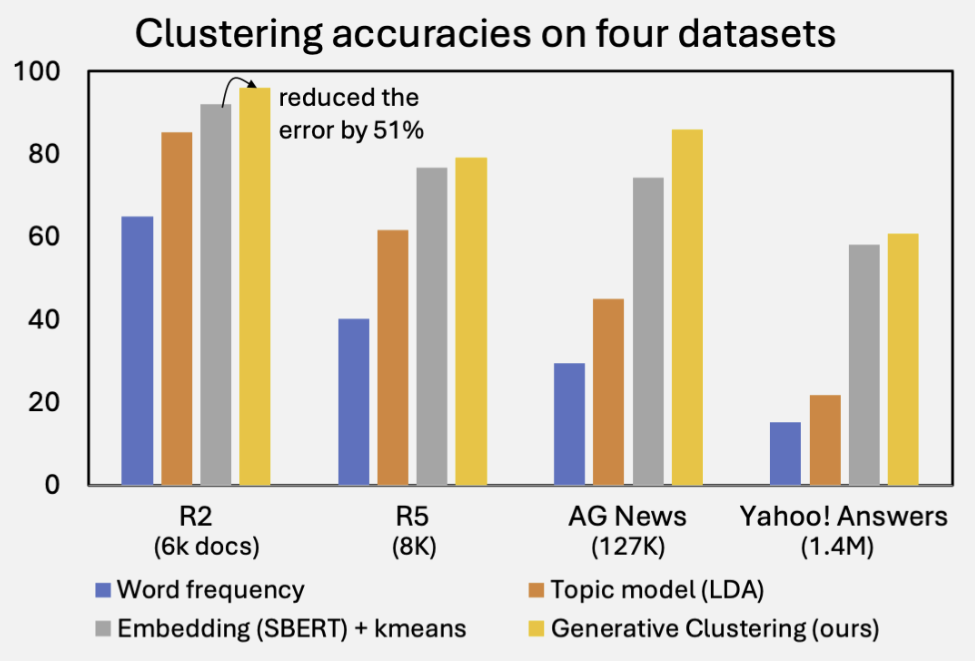
本研究では、生成言語モデルを活用することで、この古典的な情報理論的アプローチを再興します。 特に、Doc2Queryモデルを用いて、各ドキュメントを「生成されるテキストの確率分布」として表現します。この生成空間は離散かつ無限ですが、正則化付き重要サンプリング(Regularized Importance Sampling) により、その分布とKLダイバージェンスを高精度に推定します。
つまり、私たちの手法はクラスタリングと統計推定を一体として行います。実験では、4つの標準的なクラスタリングデータセットにおいて、従来の埋め込みベースの強力な手法を大きく上回る性能を達成しました。
参考文献
- Xin Du and Kumiko Tanaka-Ishii. Information-Theoretic Generative Clustering. In Proceedings of AAAI 2025. Philadelphia, USA. [link]